Zoals ik een eerdere blog heb betoogd: De beste manier om te beginnen met datagedreven werken is door te beginnen bij de beslissingen die je neemt. Klein of groot; als je iets moet beslissen en je denkt: ‘Als ik dát zou weten, dan zou het veel makkelijker zijn’. Moet je bijvoorbeeld een andere route nemen naar je werk? Als je zou weten waar vandaag de stoplichten lang op rood staan… dan zou je het wel weten.
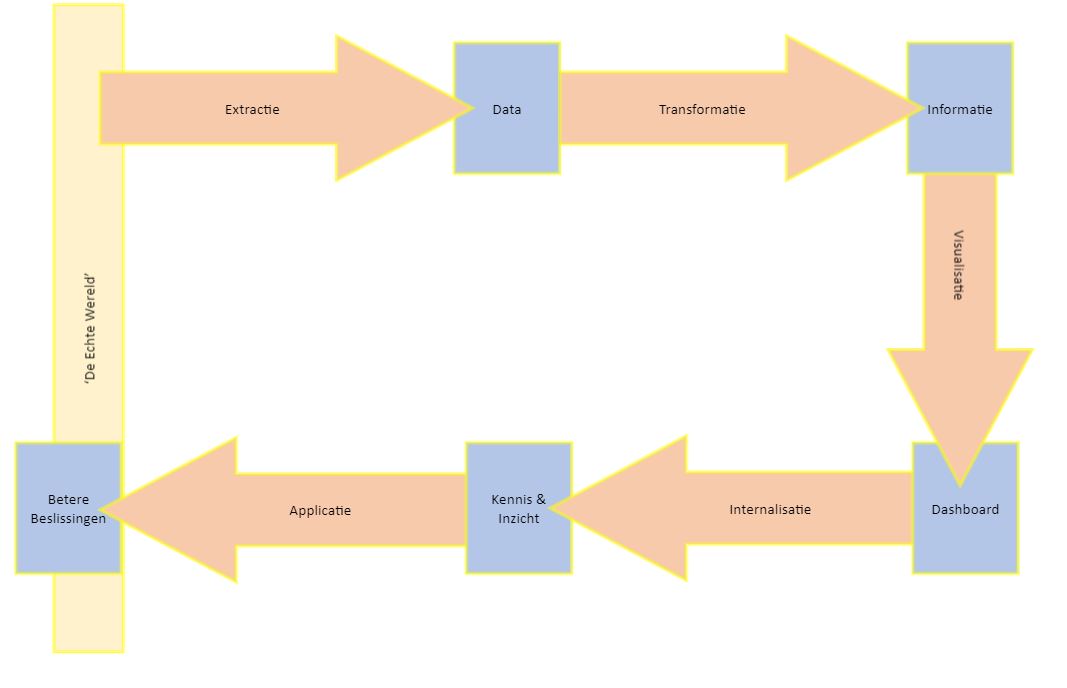
Het model dat ik hierbij gebruik is het ‘Hoefijzer model voor Datagedreven werken’.
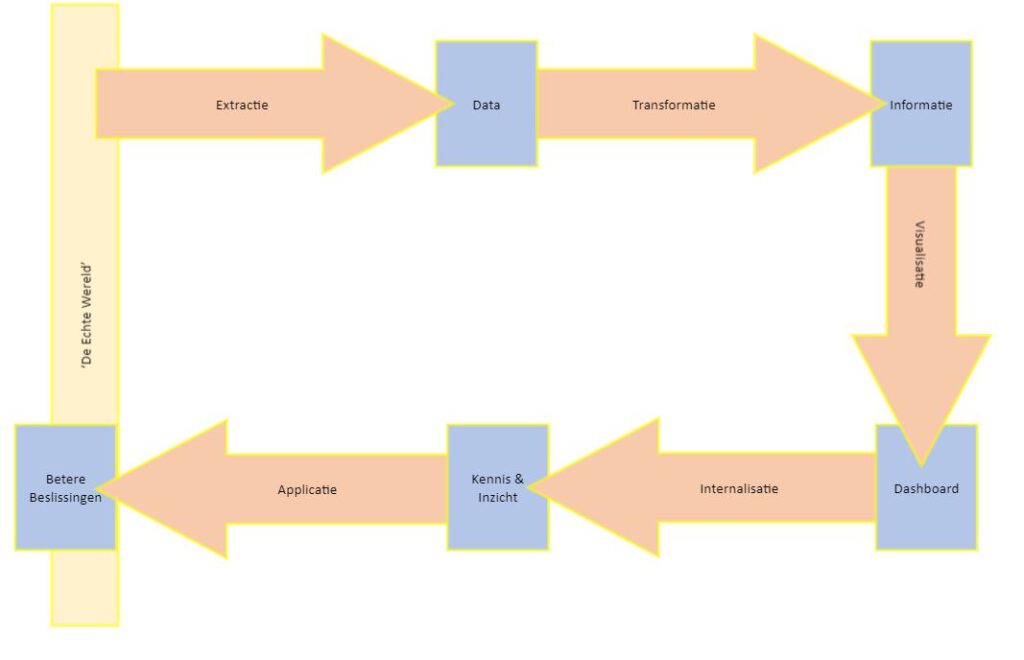
Dit model helpt mij – als informatiedeskundige – om de dialoog aan te gaan. Bij elk projectje dat je op wilt starten: Je begint altijd in de echte wereld, bij voorkeur bij de ‘Betere beslissingen’. Eventueel kun je ook beginnen aan de andere kant van het model. Dan begin je bij de echte wereld en ga je kijken naar welke data je alvast beschikbaar hebt en welke informatie je daarvan zou kunnen maken. Dit is een creatief proces, waarbij je vanuit je ruwe data probeert waarde te creëren voor je bedrijf. Dat hoop ik in een andere blog nog een keer toe te lichten.
Máár, in het beste geval begin je bij de andere kant; bij de ‘Betere Beslissingen’. Er ligt dan een vraag van een eindgebruiker die een mogelijkheid ziet om betere beslissingen, groot of klein, te nemen in de echte wereld.
Voor het ontwerp is het handig om te zien dat er 5 processen zijn, die allemaal resulteren in iets. In het ontwerpproces is het goed om deze stappen een keer voorwaarts te doorlopen, maar ook een keer achterwaarts. Eindgebruikers zijn vaak veel sterker in het achterwaarts doorlopen, omdat zij weten wat ze willen zien. Data-specialisten zijn vaak sterker in het voorwaarts doorlopen, omdat zij weten welke data er beschikbaar is, en een beter overzicht hebben van allerlei mogelijke vormen van visualisatie. De stappen van voor naar achter zijn:
- Extractie 🡪 Data
- Transformatie 🡪 Informatie
- Visualisatie 🡪 Dashboard
- Internalisatie 🡪 Kennis & Inzicht
- Applicatie 🡪 Betere Beslissingen
In het ontwerpproces begin je dus bij de achterkant! Maar als je de datastroom volgt, dan begin logischerwijs bij de Extractie. Die volgorde hanteer ik dus ook in de toelichting.
Extractie 🡪 Data
Er is een proces of voorwerp in de echte wereld waar je iets van wilt weten. In een slachterij wil je bijvoorbeeld de gewichten van de geslachte dieren weten (een voorwerp) of de snelheid van de inpakbaan (proces). Maar de enige manier om daarachter te komen is dat te meten. Dus haal je uit dat voorwerp, of uit dat proces data. Die data is in principe een tabel; soms een tabel met maar 1 kolom en 1 regel, maar meestal veel meer.
Transformatie 🡪 Informatie
Wanneer je data voorziet van context zodat het geïnterpreteerd kan worden, noemen we dat transformatie. Daarmee maak je van de data relevante informatie. Dan kan dat ene tabelletje met slechts 1 regel en 1 kolom worden voorzien van een tijdstip, en toegevoegd aan alle vorige tabelletjes, waardoor er een grote tabel ontstaat. Als er dan ook nog een beschrijving ‘Snelheid Inpakbaan’ aan toe wordt gevoegd, heb je al een tabel die echt informatie bevat.
Visualisatie 🡪 Dashboard
Dit proces is kenmerkend voor de huidige generatie van meer-en-meer datagedreven werken. Een visualisatieslag zorgt ervoor dat de beschikbare informatie gepresenteerd wordt in een format wat goed te begrijpen is voor de gebruikers. Belangrijk is dat de gebruikers voor ogen worden gehouden; welke grafische weergave kunnen zij goed begrijpen? Welke informatie is voor hun relevant, en welke non-informatie kunnen we eigenlijk allemaal weglaten uit de visualisaties? Soms zijn ze gediend met een enkele KPI, soms juist met een gestapelde staafdiagram, soms met een tabel. Een valkuil voor data-enthousiastelingen is om te veel informatie in een enkel diagram te proppen. Maar hier geldt vaak: Less is more.
Internalisatie 🡪 Kennis & Inzicht
Het internalisatie-proces is niet uniek voor datagedreven werken. Dit gebeurt bij allerlei vormen van leren en kennis opnemen. Wanneer iemand een boek leest, op cursus gaat of dit blog leest, gaat dit proces ook al lopen. Hierbij is het van belang dat de persoon in kwestie ontvankelijk is voor de informatie die aangeboden wordt. Wanneer iemand niet openstaat voor het dashboard, of eenvoudig het dashboard nooit te zien krijgt, zal dit stuk van het proces nooit gaan lopen. Ook als het dashboard niet te begrijpen is voor de gebruiker, zal de internalisatie niet plaatsvinden. Een goede leidraad is dat nieuwe kennis altijd aansluit bij bestaande kennis. Het dashboard uit de vorige stap moet dus net wat meer vertellen dan de gebruiker nu al weet – maar niet de lat zo hoog leggen dat hij eerst Engels moet leren of Mekko-diagrammen moet gaan begrijpen.
Applicatie 🡪 Betere Beslissingen
Dit sluitstuk van het grote proces berust op de opgedane Kennis en Inzicht. Als je je kennis en inzicht toepast, kun je betere beslissingen maken dan wanneer je dat niet doet. Dit proces loopt eigenlijk onafhankelijk van de vraag waar je die kennis of inzichten vandaan haalt en is dus niet uniek voor datagedreven werken. Bijv. mensen die niet eens kunnen lezen of schrijven, maar wel op tijd de grond ploegen en gewassen zaaien, passen hun kennis toe om betere beslissingen te maken.
De menselijke factor bij de laatste twee stappen is groot; en voor de data-werkers onder ons: Dat is buiten je eigen bereik, maar van essentieel belang voor het succes van datagedreven werken.
Voor succesvol datagedreven werken moeten alle deze stappen goed doorlopen worden. En het helpt mij – wanneer een dashboard/project niet de verwachte impact heeft – om het probleem te analyseren. Krijg je de data niet goed uit de systemen, krijg je de koppeling met de omliggende data niet goed of sluit de visualisatie niet aan bij het kennisniveau van de eindgebruikers? Of kun je zelfs concluderen dat de eindgebruikers het nu wel beter weten, maar de kennis niet in de praktijk brengen? Als je weet waar het probleem ligt, dan heb je het al voor de helft opgelost.