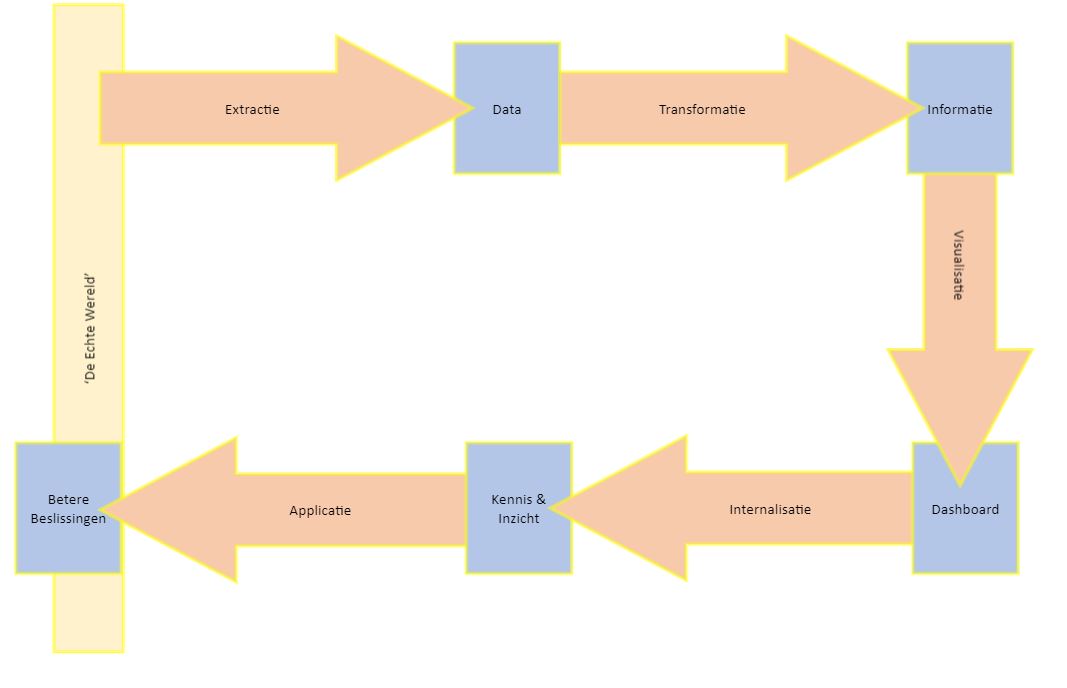
In een eerder blog heb ik uiteengezet hoe je via bovenstaande 5 stappen kunt beginnen met datagedreven werken.
De echte wereld
Vandaag wil ik me focussen op de eerste stap: Door middel van Extractie – Data maken. Als je naar het hoefijzer-model kijkt, zie je dat de Extractie aansluit op de ‘Echte Wereld’. De echte wereld is een product of een proces. Er zijn meer zaken die je kunt meten (meningen, personen, omstandigheden) maar ik ben in de praktijk tegengekomen dat je vooral data verzamelt over producten of processen.
Producten, processen en omstandigheden
Een product; dat kan bijvoorbeeld een plastic beker zijn. Als het een fysiek voorwerp is, dan heeft het eigenschappen die je kunt vaststellen. Zo kunnen we van onze plastic beker vaststellen wat de inhoud is, wat de dikte van het plastic is, wat de kleur is en ook welk materiaal er gebruikt. Deze eigenschappen zijn in principe onveranderlijk. We kunnen ook de temperatuur vaststellen (erg belangrijk als deze beker net uit de mal komt), maar dat is een eigenschap die wél kan veranderen.
Bij het vaststellen van deze data is het van belang om je af te vragen of deze eigenschappen redelijkerwijs veranderlijk zijn. Als een eigenschap veranderlijk is, dan moet niet alleen de waarde van de eigenschap worden gemeten, maar ook het tijdstip waarop deze waarde is gemeten worden vastgelegd. Wanneer een gemeten waarde onveranderlijk is, is dat ook meteen een mogelijkheid om bij een eventuele controle te kijken of de vastgelegde informatie nog steeds correct gekoppeld is aan het fysieke product.
Processen kunnen ook worden gemeten. Dan kan je kijken naar de snelheid van produceren. Bij het verzamelen van data omtrent processen is de tijdsfactor altijd cruciaal. Bij processen kan er worden gemeten of worden geteld. Bijvoorbeeld het aantal producten per uur/per dag.
Naast het meten van producten en processen kunnen ook omstandigheden worden gemeten. Bijvoorbeeld de buitentemperatuur, luchtvochtigheid, het aantal aanwezige personen in een ruimte of de geluidsbelasting. Net als bij processen is ook hier de tijdsfactor van essentieel belang. Een belangrijk verschil is dat de omstandigheden eigenlijk altijd factoren zijn die buiten de sfeer van invloed liggen.
Meten of vastleggen
Als we deze eigenschappen automatisch vastleggen, dan noemen we dat meten. Of om meteen maar een jargon-term er tussen te gooien: ‘Sensor-generated data’ of sensordata. Sensordata heeft als eigenschap dat het vaak erg consistent en zonder veel moeite in enorme hoeveelheden gegenereerd kan worden. Het nadeel van sensordata is dat er vaak systematische afwijkingen optreden. Zo kan een temperatuursensor die verkeerd is gekalibreerd dagenlang een afwijking van 5 graden geven. In je oven niet zo erg, maar in je koelkast leidt dat rotte tomaten en bedorven melk.
Het alternatief voor meten is handmatig vastleggen. Dat gebeurt typisch met een productieapplicatie of het met welbekende programma Excel. Bij het opzetten van datagedreven werken is Excel van grote waarde. Doordat het wijdverbreid is kunnen veel mensen er mee werken. Excel heeft ook zijn beperkingen, het is bijvoorbeeld lastig om datakwaliteit af te dwingen met Excel; doordat veel mensen het kennen zijn ze ook in staat om buiten de originele bedoeling om te werken. Zo heb ik zelf meegemaakt dat de gebruikers uit een lokale kopie van de data gingen werken. Of dat ze een kolom verwijderden, omdat ze die niet nodig vonden. (Maar die verderop in het proces van groot belang was.)
Bij het verder implementeren van datagedreven werken zul je eerder kiezen voor dedicated applicaties en van Excel afstappen. Een goed ontwerpprincipe is dat het meten of vastleggen van de data het primaire productieproces zo min mogelijk verstoord.
Een ander goed ontwerpprincipe is dat je de data maar op 1 plek vastlegt, en de data leg je maar 1 keer vast. Uiteraard kan je wel kopieën van de data vastleggen, maar er blijft 1 bron van de waarheid. (Single Source of Truth).
Data
Wanneer je dan klaar bent met het extracten van de data heb je opeens data. De meest voorkomende vorm van data is data die wordt vastgelegd. Dat veronderstelt dat er ook data is die niet wordt vastgelegd – en dat klopt. Zogeheten ‘streaming data’ is een onafgebroken stroom aan data die meteen wordt verwerkt en alleen wordt vastgelegd als er een afwijking is. Je kunt het vergelijken met de stoppen in je huis. Constant wordt er stroom doorheen gestuurd en alleen als die te hoog is, dan wordt er ingegrepen. Op die manier kun je aan het begin al filteren en de hoeveelheid data sterk reduceren.
Je al dan niet gereduceerde data wordt vastgelegd en komt tot rust in een opslag. Dat is typisch een database of een bestand. Een verzameling van losse tabellen die nu in alle rust verder bekeken kan worden zonder dat het primaire proces er door wordt verstoord.
Datakwaliteit
Op een verzameling data kan je analyses uitvoeren omtrent de datakwaliteit. Er zijn tal van criteria die je kunt toepassen op de verzameling van data en welke daarvan belangrijk zijn hangt sterk af van het doel waarvoor de data uiteindelijk gebruikt wordt. Enkele voorbeelden zijn: Accuraatheid, Precisie, Betrouwbaarheid, Geloofwaardigheid, Timeliness, Volledigheid, Syntax Consistentie en Semantische Consistentie, Context, Validiteit etc.
Bij datakwaliteit is het van belang dat het ‘goed genoeg’. Dat wordt inderdaad bepaald door het doel waarvoor de data wordt verzameld. Voor een actuele snelheid van een voertuig moet de data vooral snel beschikbaar zijn en zal er meer nadruk moeten worden gelegd op de timeliness. Voor het verloop van de snelheid gedurende de dag zal de timeliness minder belangrijk zijn, maar komt er juist nadruk op volledigheid.
Voor het krijgen van inzicht in de effectiviteit van je medewerkers kun je prima toe met data waarbij er af en toe een mistelling plaatsvindt. Of een medewerker nu 125 dozen per uur heeft gepickt of 128, dat maakt niet zoveel uit. Het is vooral zorgwekkend dat die andere medewerker er maar 40 of 42 heeft gepickt. Maar voor het factureren naar de klant is de accuraatheid opeens wel van groot belang. Een klant die 125 dozen heeft besteld en er maar 128 gefactureerd krijgt; die gaat niet blij worden.
Datacontext
We nemen alvast een voorschot op de volgende stap: Transformeren. Dat is door context aan de data toe te voegen. Context betekent dat het datapunt een toelichting krijgt om door mensen geïnterpreteerd te kunnen worden. Sommige datapunten hebben in zichzelf al context: ’20-09-2021’; dat zal waarschijnlijk een datum zijn. ‘Gouda’; dat zal waarschijnlijk een plaats zijn – maar misschien is het wel een type kaas. Maar 15.0⁰? Is dat een temperatuur? Of een hoek? Daarom is het een goed principe om data al te voorzien van context. Als het gaat om tabellen; voorzie die tabellen van kolomnamen die voor een mens begrijpelijk zijn. Dus niet ‘i328’; maar gewoon ‘DebiteurNummer’ als kolomnaam. Ook het niveau daarboven: Tabelnamen – geef die ook een begrijpelijke naam. Dat maakt de volgende stap veel eenvoudiger. Dan kun je zoeken op het ‘Saldo’ uit de tabel ‘Debiteuren’ in plaats van dat je dat opnieuw moet afleiden.