
Deze blog is de tweede blog in de serie van 5: Hij sluit aan op ‘Met Extractie naar Data’ en past bij de volgende stap van het hoefijzer-model; met transformatie naar informatie.
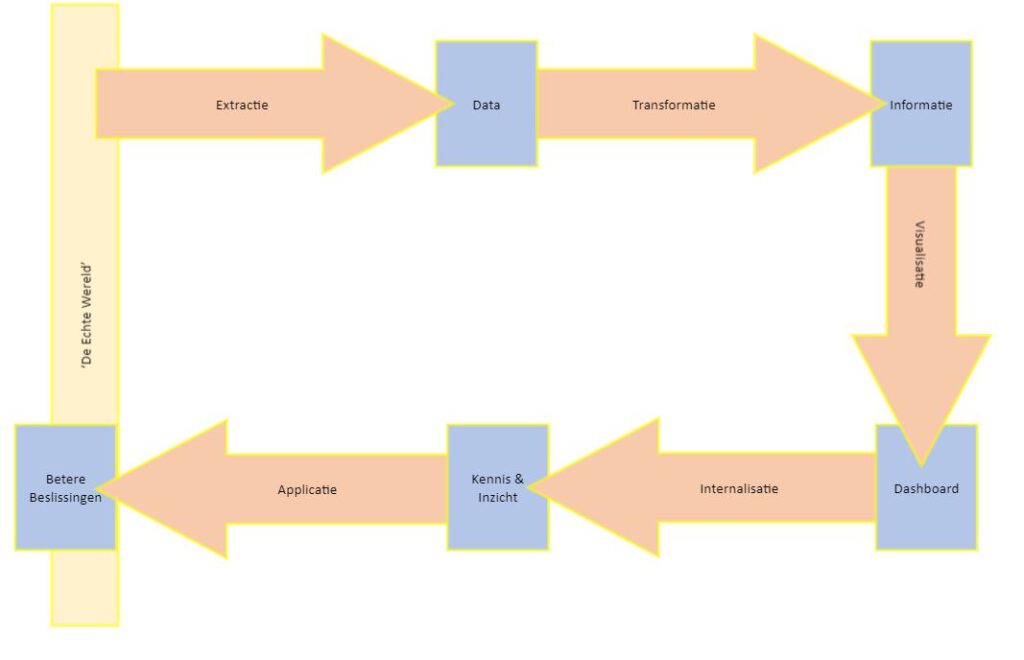
Data
We beginnen onze transformatie naar informatie met data. We hebben namelijk wel iets van input nodig; en in dit geval is dat data. Die hebben we in de vorige stap uit de bronapplicatie gehaald. Die data willen we transformeren naar informatie. Soms is die scheidslijn heel erg dun en is de transformatie naar informatie eigenlijk alleen het 1-op-1 overzetten van de data. Je kunt dit bijvoorbeeld zien aan een landentabel. De data in de landentabel (LandNaam, LandCode, Afkorting, Valuta) is eigenlijk al rijk genoeg om als informatie door het leven te gaan.

In de transformatiestap besteden we aandacht aan een aantal zaken. Deze aandachtspunten loop je een voor een langs in de verschillende stappen. Deze stappen helpen om van ruwe data bruikbare informatie te maken. Hierbij is er een duidelijk verschil tussen de extractie die we eerder bespraken en transformatie.
In mijn eigen werk gebruik ik voor de Extracties een plaatje van een jaknikker en voor de Transformaties het plaatje van een raffinaderij. Die analogie gaat verder: Extractie gaat vooral om grote hoeveelheden gecontroleerd uit databronnen krijgen. Transformatie gaat om het bewerken van die ruwe data tot brandstof, smeermiddel en lampenolie voor de organisatie. De stappen die we maken liggen niet vast qua volgorde en zijn allemaal optioneel; je kunt ze overslaan. Maar je zult zien dat elke stap toegevoegde waarde heeft om de informatie bruikbaar te maken. De stappen die ik gebruik zijn:
- Voorzien van context
- Data ontdubbelen
- Human-Readable maken
- Uitrekenen
- Consistent maken
- Koppelpunten aanleggen
Voorzien van Context
We voorzien de data van context. Dat kan op allerlei manieren. Vaak is het toevoegen van de specifieke bron en tabel een logische eerste stap om te zorgen dat de data context krijgt. Een veld als ‘klantadres’ mag volledig helder zijn in de context van een factuuradministratie, maar diezelfde klant heeft een heel ander ‘klantadres’ in de transportadministratie. Daarom verander je in deze transformatiestap het ‘klantadres’ in ‘klantfactuuradres’ en ‘klantafleveradres’.
Data Ontdubbelen
Je komt regelmatig dubbele data tegen in de praktijk. Klanten die tweemaal zijn ingevoerd, dubbel verzonden facturen of vier versies van hetzelfde product. Die data wil je op een goede manier ontdubbeld hebben. Natuurlijk is de beste plek om dat te doen in de bronapplicatie zelf. Die dubbele klant wil je er meteen uit hebben. Maar aangezien dat niet altijd mogelijk is, moet je soms zelf nog aan de slag met het ontdubbelen van de data. De grootste uitdaging hierbij is de sleutel waarmee je bepaalt of iets een dubbel record is. Zijn de heren A. de Prins en E. de Prins, allebei geboren op 01-02-2003 en woonachtig op hetzelfde adres, dubbel of een tweeling? En idem voor de twee Anne Maties, met twee verschillende geboortedatums? Is dat een foutje of een getrouwd stel?
In de praktijk zal je tegenkomen dat bij bijvoorbeeld naamswijzigingen er een nieuwe klant wordt aangemaakt. Dan kom je na verloop van tijd tegen dat de historische data van die klant incompleet geworden is.
Maak de velden Human-readable
Zorgen dat mensen de data begrijpen is een belangrijke stap om van data informatie te maken. Bijvoorbeeld: De klantnummers in de verkopen-tabel moeten worden vervangen door (of aangevuld worden met) klantnamen. Dat is verrijking op het gebied van ‘begrijpelijkheid.’ Het is een goed gebruik om de data in deze stap human-readable te maken. Dat betekent concreet dat alle kolomnamen begrijpelijk moeten zijn, dat nummers vervangen zijn door namen en dat de meest logische eenheden worden gebruikt. Dus vervang je dollarcenten door euro’s, vervang je de pounds door kilo’s en vervang je de seconden door dagen.
Uitrekenen (integreren en afleiden)
Daarnaast moeten er soms dingen worden uitgerekend die niet op die manier worden bijgehouden. Als er bijvoorbeeld 1000 kilo vlees wordt geleverd voor een bedrag van €2500. Dan is dat €2,50 per kilo, maar dat moet wel even worden uitgerekend. Uiteraard is dit voorbeeld simplistisch: In het echt moet je nog corrigeren voor transportkosten, korting, retouren en verpakking. Al die informatie moet (mits het voldoende impact heeft) worden verwerkt tot iets wat én begrijpelijk voor mensen is, en wat ook nog eens de waarheid voldoende benadert.
‘Voldoende benaderen’ heeft natuurlijk alles met het uiteindelijke doel te maken. De informatie die je nodig hebt om een inschatting van de verkopen van komend jaar te maken hoeft minder accuraat te zijn dan de informatie die je nodig hebt om een terugroepactie te coördineren. En de data voor de planning van morgen moet vele malen meer up-to-date zijn dan de data die je nodig hebt om het energieverbruik van de afgelopen maanden in kaart te brengen.
Twee bijzondere vormen van uitrekenen verdienen de aandacht. Integreren en Afleiden. Het integreren gaat om het uitrekenen van totalen. Wanneer je de dagelijkse productie als datapunt doorkrijgt, dan wil je de totale jaarproductie berekenen door alle voorgaande dagproducties bij elkaar op te tellen.
Het afleiden gaat juist de andere kant op. Als je dagelijks de meterstanden van je gas, water en elektra uitleest, wil je juist afleiden. De eindstand is nauwelijks van belang: Die telt alleen maar door. Maar juist de afgeleide, de eindstand van vandaag minus de eindstand van gisteren vertelt iets over je dagelijkse gebruik en kan je iets vertellen over de besparingsmaatregelen die je hebt genomen.
Consistentie
Een ander aandachtspunt is consistentie. Er zijn twee verschillende vormen: Syntactische Consistentie en Semantische Consistentie. Syntactische Consistentie gaat er over dat je de data altijd op dezelfde manier wegschrijft. Je ziet dit vaak bij telefoonnummers; een en hetzelfde nummer kan je schrijven als:
06-12 34 56 78
+316 12345678
0612345678
0031-612 345 678
En idem voor postcodes:
1234AB
1234 ab
1234-AB
In de transformatie naar informatie wil je al deze varianten reduceren tot 1 variant. Dat betekent in het geval van postcodes dat je alle spaties en leestekens verwijdert en alle kleine letters vervangt door hoofdletters. Dit zorgt ervoor dat in de Analyse fase alle postcodegebieden goed met elkaar vergeleken kunnen worden. Ook kun je hier goed een check op validiteit invoegen: Een postcode moet bestaan uit 4 cijfers en 2 letters. (Tenzij je natuurlijk klanten over de grens hebt…)
Semantische consistentie gaat er juist over dat de data hetzelfde betekent. Dat kan je tegenkomen op allerlei plekken waar mensen iets vast willen leggen wat niet standaard door de software wordt gefaciliteerd. Zelf ben ik het bijvoorbeeld tegengekomen bij kredietlimieten. Een kredietlimiet van €1 werd opgegeven als het krediet was geweigerd. Op zich werkbaar, maar als je dan de relatieve overschrijding wilt gaan uitrekenen, krijg je vreemde effecten: Klanten die 1000x hun kredietlimiet overschrijden. Maar dat komt omdat die €1 inhoudelijk iets anders betekent dan de €100.000 van de volgende klant.
Vergelijkbare effecten kan je hebben bij ‘uitkeringsdatum’ van een verzekering. Een lijfrente of pensioen die ‘tot uitkering komt’ kan de maand daarna nog een keer ‘tot uitkering komen’. Een uitvaartverzekering kan dat zeker niet. Dergelijke verschillen kun je het beste splitsen over meerdere velden. Dit vergt uiteraard enige achtergrondkennis over het domein waarover de informatie gaat.
Leg de koppelpunten aan.
EeEen laatste punt van aandacht bij de transformatie naar informatie is het aanbrengen van Koppelpunten. Hoe kan de informatie die je nu verzamelt straks verder worden gelinkt aan andere informatie? De klanten aan de klant-tabel, de producten aan de product-tabel en de transporteurs aan de transporteurs-tabel. Als die tabellen al bestaan is het een goed gebruik om de namen van die kolommen te laten overeenkomen met de kolommen in de doeltabellen. Dus: klant_id koppelt met de klant-tabel, product_id met de product-tabel et cetera.
Naar Informatie
Zoals hierboven te lezen is, is er veel dat je in de transformatie naar informatie kunt aanpakken. De Transformatie is dé aangewezen plek om de samenhang tussen de verschillende bedrijfsonderdelen en de verschillende applicaties vorm te geven. Als jij de data beter bent gaan begrijpen, dan gebruik je de transformatie om dat vast te leggen. De aandachtspunten hierboven geven je de handvatten om dit goed uit te voeren.
Maar als je wilt beginnen met datagedreven werken is de hele lijst van aandachtspunten hierboven allicht teveel van het goede. Pak er uit wat voor jou, in deze situatie, relevant is.
Gelukt? Dan volgt de leuke, volgende stap, het visualiseren van de verwerkte data!